QUNIS hat bei Melitta Single Portions ein Data Warehouse implementiert und betreut seitdem den Betrieb und die Weiterentwicklung der Cloud-Lösung. Mit „QUNIS Care & Run“ erhält das junge Unternehmen professionellen Rundum-Service und kann sich verstärkt auf den Ausbau seines innovativen Geschäftsmodells konzentrieren.
QUNIS ist Teil unseres Teams. Der Elan und die Motivation im Team machen die Zusammenarbeit so besonders und bringen uns täglich voran.
Angela Musić-Siedler,
BI-Leiterin, Melitta Single Portions
![]()
Data Warehouse für innovatives Start-up
Seit 2019 hat sich Melitta Single Portions mit seiner Marke Avoury® am Markt für einzelportionierten Tee positioniert. Parallel hat das Unternehmen seine IT-Landschaft komplett neu „auf der grünen Wiese“ aufgesetzt, inklusive Data Warehouse als Grundlage für das Reporting und die Unternehmenssteuerung.
Die BI-Leiterin Angela Musić-Siedler, die das Thema anfangs allein bearbeitete, holte sich im Jahr 2019 QUNIS als erfahrenen Beratungs- und Implementierungspartner zur Seite. Die Zusammenarbeit startete mit einem Workshop zur Konzeption des Data Warehouse. Auch die Produktauswahl hat QUNIS begleitet. Als Technologien sind Microsoft Azure SQL und das Frontend Pyramid Analytics im Einsatz.
Mit der Cloud-Lösung kann das Start-up-Unternehmen die Kosten sicher planen und die benötigten IT-Ressourcen entsprechend dem Firmenwachstum schnell ausbauen. Das Frontend wurde drei Jahre nach der Inbetriebnahme erneut evaluiert und weiterhin als die passende Lösung bestätigt.
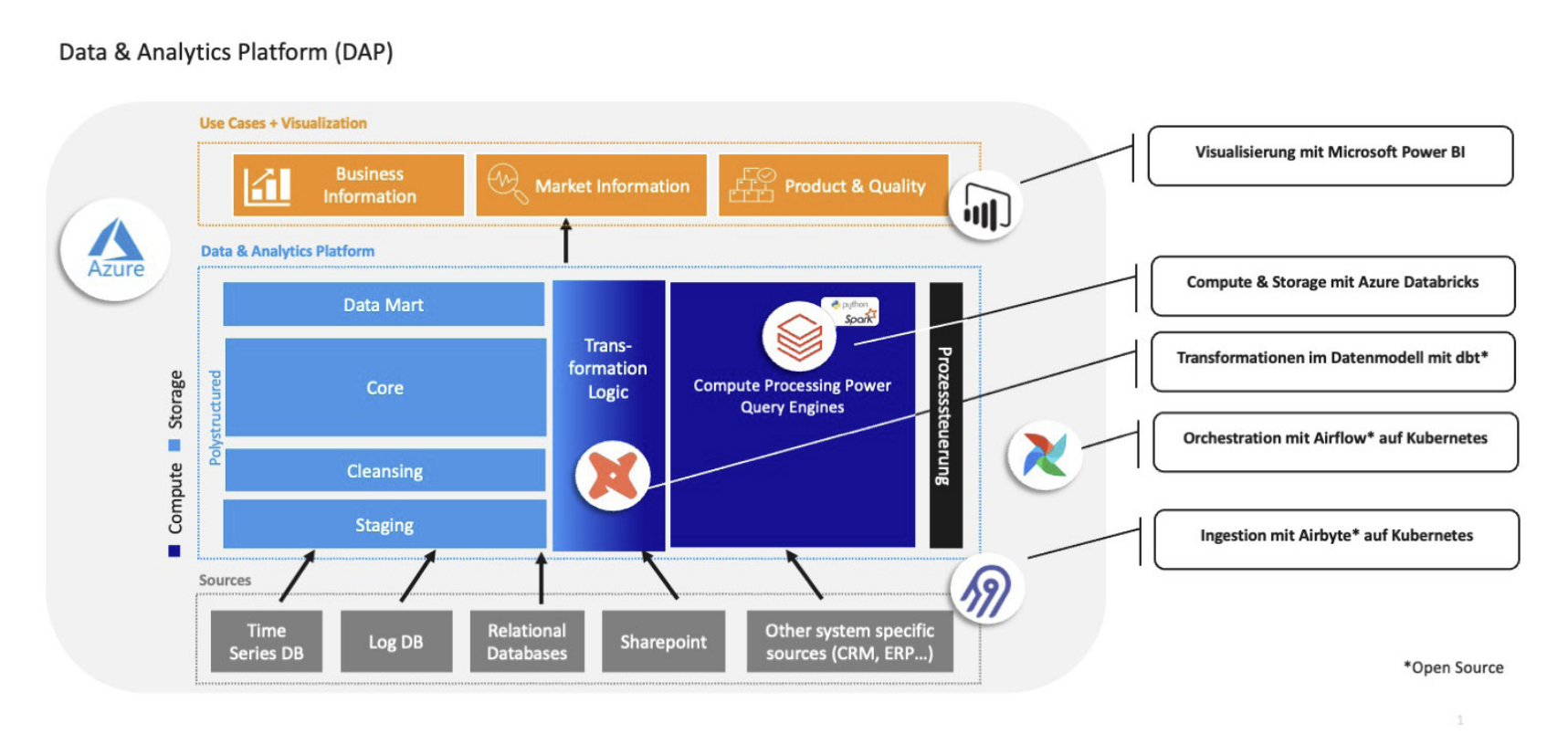
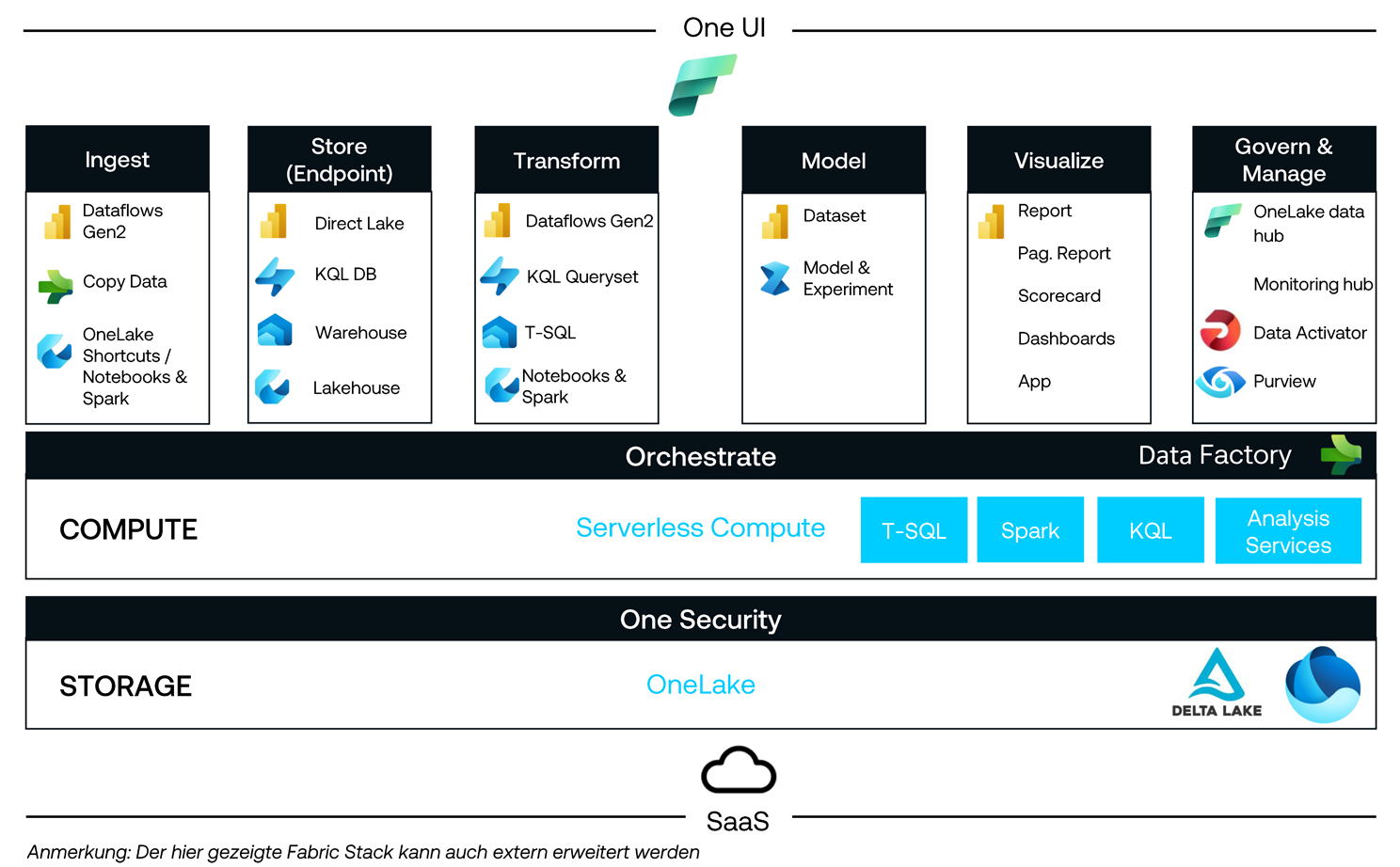
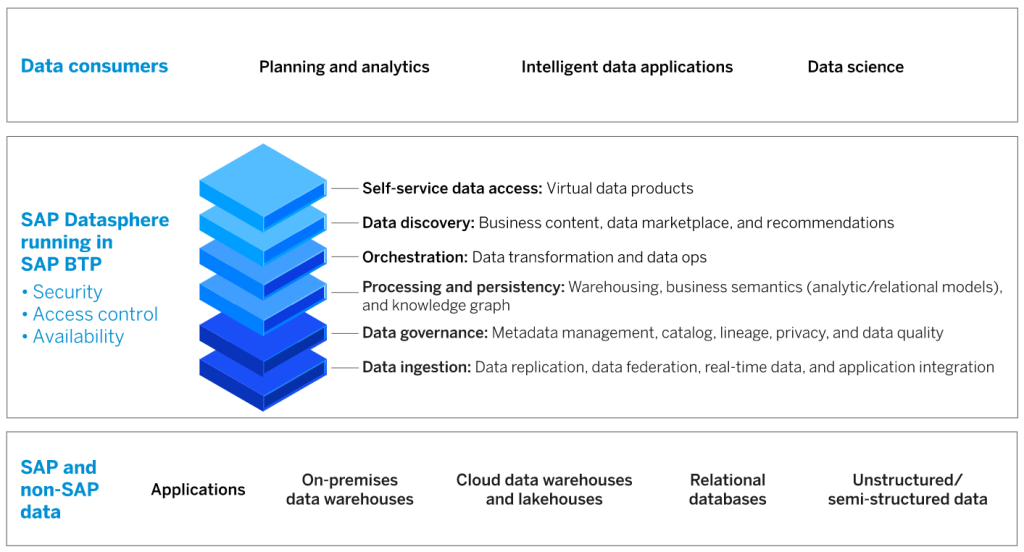
Die Implementierung fand auf Basis des QUNIS Data Warehouse Framework (QDF) statt, das die effiziente Umsetzung einer standardisierten und hoch automatisierten IT-Architektur gewährleistet. QUNIS hat verschiedene Datenquellen wie SAP, Salesforce oder Google Analytics zu einer zentralen Datenbasis für das Reporting zusammengeführt. Inzwischen sind rund zehn Vorsysteme integriert.
Standardreports für jeden Fachbereich
Hinsichtlich des Standardreportings lautete das Ziel, dass von Anfang an jeder Fachbereich einen Bericht mit seinen wichtigsten Kennzahlen erhalten sollte.
Eine wesentliche Herausforderung bestand dabei im neuen Geschäftsmodell des Startups: Da zum Zeitpunkt der Implementierung die Produkte noch nicht auf dem Markt waren, lagen noch keine konkreten Verkaufszahlen für die Belegung der Datenmodelle und Berichte vor. Avoury® arbeitet über den eigenen Shop mit dem DTC (Direct to Consumer)-Ansatz. Das Kundenverhalten und die Kundenzufriedenheit sind dabei ein zentrales Thema der BI-Analysen.
Inzwischen gibt es 45 Berichte für alle Fachbereiche. Die Schwerpunkte liegen derzeit auf dem Ist-Reporting von Sales- und Finanzkennzahlen; die Planung soll in einem späteren Ausbauschritt dazukommen. Einen Überblick über die wichtigsten Steuerungskennzahlen ruft die Geschäftsführung täglich auf ihrem Smartphone ab.

Steuerungsinformationen aus der Teemaschine
Wertvolle Steuerungsinformationen liefern zudem die verkauften Avoury® Teemaschinen. Nach Zustimmung durch den Kunden kann Melitta Single Portions den Lebenszyklus, Updates oder Wartungsdaten der smarten Maschinen online auslesen. Im Servicefall hat so der Melitta-Support Zugriff auf die Daten und kann den Endkunden gezielt unterstützen. Auch Nutzungsinformationen wie die verwendeten Teesorten erkennt die Maschine.
Durch die Auswertung der Maschinendaten erhält Melitta Single Portions Einblick in das Kundenverhalten, zu dem es bislang wenig Erfahrungs- und Vergleichswerte gab. Auch die Klassifizierung und Analyse von Retouren liefern Hinweise für das Qualitätsmanagement und die Erhöhung der Kundenzufriedenheit.
Durch die BI-Lösung kennen wir unsere Kunden, können gut informierte Entscheidungen treffen und unser Unternehmen gezielt steuern.
Strukturierte Weiterentwicklung
Für die Weiterentwicklung des Berichtswesens hat das Team ein strukturiertes Anforderungsmanagement etabliert.
- Die Aufnahme und Spezifikation der Anforderungen aus den Fachbereichen übernimmt Melitta Single Portions intern.
- QUNIS sorgt dann für die Umsetzung im Backend: den Datenload aus den Vorsystemen, den Aufbau von Business-Logiken und den standardisierten Ausbau des Datenmodells.
- Die gemeinsame Entwicklungsarbeit erfolgt in einem agilen Ansatz mit definierten Sprints. Zur Planung der Sprints samt Personaleinsatz nutzt das Team Azure DevOps.

Sicherheit durch QUNIS Care & Run
Außer der Entwicklung unterstützt QUNIS auch den Systembetrieb. Im Rahmen der Care & Run Services kümmert sich das Support- und Wartungsteam von QUNIS um die Produktiv- und Testumgebung des Data Warehouse in der Azure Cloud.
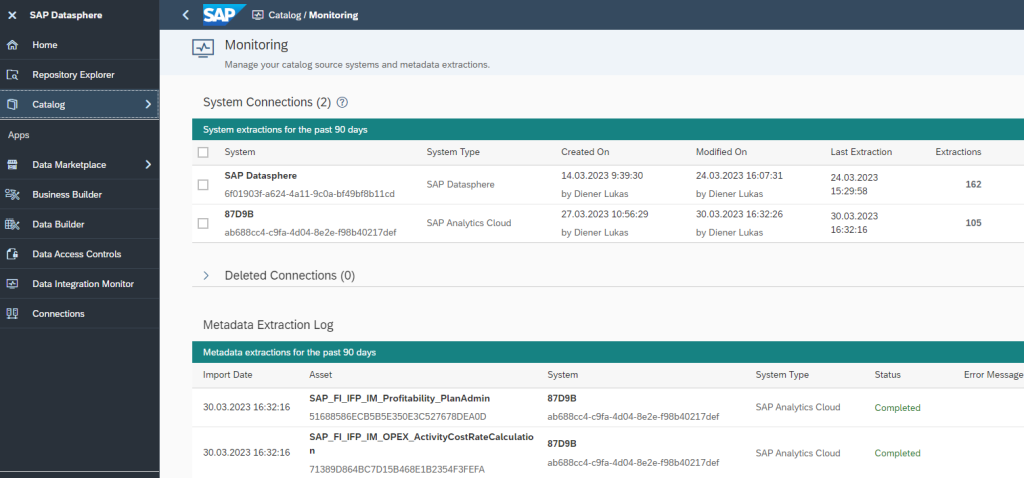
So prüfen die IT-Experten täglich, ob der nächtliche Datenload zum Data Warehouse störungsfrei abgelaufen ist. Gründe für einen abgebrochenen Ladelauf können u .a. Wartungsarbeiten an einem der Vorsysteme innerhalb der Melitta Group oder die Passwortänderung einer Datenquelle sein, die dann für die BI-Anwendung nachgezogen wird.
Durch Fehler-Alerts, ein strukturiertes Ticketsystem und die Bearbeitung auf Basis definierter SLAs gewährleistet QUNIS den durchgängig sicheren und stabilen Systembetrieb.
In monatlichen Meetings bespricht das BI-Team mit den Experten von QUNIS Themen wie inhaltliche Auffälligkeiten, Möglichkeiten zur weiteren Automatisierung oder effiziente Kommunikationsregeln, um den Systembetrieb kontinuierlich weiter zu optimieren. Einige Erkenntnisse aus dieser Zusammenarbeit sind bereits in die Weiterentwicklung der QUNIS Care & Run Services eingegangen.
Hohe Planungssicherheit
Die Zusammenarbeit mit QUNIS ermöglicht Melitta Single Portions auch mit weniger Personalressourcen den Betrieb und Ausbau einer professionellen und hochmodernen Berichtsumgebung. In Kombination mit der Cloud-Infrastruktur sind die Personal- und IT-Ressourcen gezielt skalierbar.
Das BI-Team kann flexibel auf Anforderungen aus dem Unternehmen reagieren und sich dabei jederzeit auf eine stabile IT-Umgebung verlassen. Bei Fragen stehen fachlich und technisch versierte Ansprechpartner von QUNIS zur Verfügung, die die gemeinsam entwickelte Systemlösung selbst gut kennen.
Wir schätzen die Kompetenz und Zuverlässigkeit
der QUNIS Experten und die Zusammenarbeit macht einfach Spaß.
Mehr zu Melitta Single Portions: Melitta Single Portions ist innerhalb der Melitta Group für Produkte rund um die Heißgetränkezubereitung in Form der Einzelportionierung zuständig. Mit innovativen Lösungen und Produkten ist es das Ziel, einer der führenden, global agierenden Anbieter für einzelportionierte Heißgetränke zu werden. Seit November 2019 wird mit Avoury®, der ersten Marke von Melitta Single Portions, einzelportionierter Tee im Premium-Sortiment produziert und vertrieben. Mit der Avoury® One Teemaschine und über 30 Premium-Teesorten sorgt Avoury® für einen neuen, nachhaltigen und hochwertigen Teegenuss. www.melitta-group.com
Mehr zur QUNIS Implementierung