Artificial Intelligence (AI) nutzt Machine Learning
Artificial Intelligence ist ein Begriff, der sofort sehr stark mit Innovation assoziiert wird und gleichermaßen eine große Faszination wie diffuse Ängste auslösen kann, obwohl oder vielleicht auch gerade weil es bis dato keine generell akzeptierte oder allgemeingültige Definition dessen gibt.
Sprach Richard Bellman 1978 beispielsweise von „der Automatisierung von Aktivitäten, die wir mit menschlichem Denken assoziieren, also dem Fällen von Entscheidungen, Problemlösung, Lernen …“, definierte Patrick Henry Winston 1992 die AI als „das Studium von Berechnungen, die es möglich machen, wahrzunehmen, schlusszufolgern und zu agieren“. Eine weitere Definition aus dem Jahre 1990 von Ray Kurzweil trifft es ebenso im Kern: „Die Kunst, Maschinen zu entwickeln, die Funktionen ausüben, welche Intelligenz erfordern, wenn sie vom Menschen ausgeführt werden.“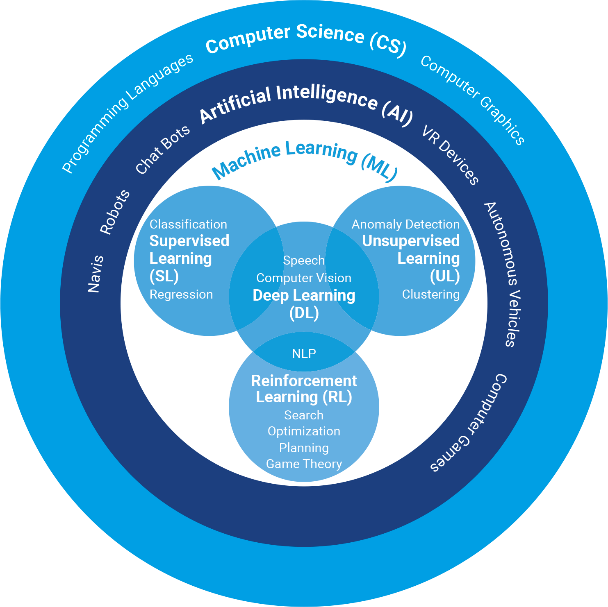
Ein Großteil der Methoden, mit denen Artificial Intelligence (AI) realisiert wird, fasst man unter dem Oberbegriff des Machine Learning (ML) zusammen. Maschinelles Lernen ist sehr stark der Art nachempfunden, wie wir Menschen lernen – so werden der Maschine in immer wiederkehrenden Schleifen Beispiele vorgelegt, anhand derer ein Sachverhalt gelernt wird, nur um das Gelernte anschließend verallgemeinern zu können.
Beispielsweise zeigt man der Maschine zahlreiche verschiedene Bilder von Katzen, auf dass sie danach das Prinzip „Katze“ verinnerlicht hat und solche auch auf Bildern erkennen kann, die sie vorher noch nicht zu sehen bekommen hat. Wie auch beim Menschen wird beim maschinellen Lernen nach der Lernmethode unterschieden – so unterscheiden wir zwischen dem überwachten Lernen (Supervised Learning), also dem Lernen anhand vordefinierter Beispiele, dem unüberwachten Lernen (Unsupervised Learning), was das automatische Erkennen von Mustern oder Merkmalen zum Inhalt hat, sowie dem bestärkenden Lernen (Reinforcement Learning), das auf dem Prinzip des Belohnens und Bestrafens basiert.
Advanced Analytics nutzt AI
Bei der Advanced Analytics kommen maschinelles Lernen sowie andere mathematisch-statistische Verfahren und Modelle zur Anwendung. Hierunter verstehen wir das methodische Analysieren und Interpretieren von Daten beliebiger Strukturen mit Ziel einer möglichst automatischen Erkennung von Bedeutungen, Mustern und Zusammenhängen und/oder der Prognose bestimmter Eigenschaften oder Kennzahlen.
Die Advanced Analytics kann somit auch als nächste Evolutionsstufe der Business Intelligence gelten. Während die traditionelle Business Intelligence den Blick vorrangig in die Vergangenheit richtet, um den Manager zu ermächtigen, die richtigen Rückschlüsse und bestmöglichen Entscheidungen für die künftige Ausrichtung des Unternehmens zu treffen, versucht die Advanced Analytics, diesen Prozess weitestgehend der Maschine zu überlassen, also zu automatisieren und selbst in die Zukunft zu schauen. Dies erfolgt in zwei aufeinanderfolgenden Schritten – im ersten werden durch die Predictive Analytics Vorhersagen über zu erwartende Entwicklungen gemacht, im zweiten zeigt die Prescriptive Analytics potenzielle Maßnahmen auf, gezielt wünschenswerte Ergebnisse zu erreichen.
Big Data erweitert BI
Wie auch in des Managers Entscheidungsprozess weitere relevante Zusatzinformationen neben den reinen Geschäftsergebnissen einfließen, beispielsweise Wetterdaten, geolokale Informationen oder Markttrends, so ist dies analog gültig für die Advanced Analytics. So beschafft man sich neben den strukturierten Daten aus ERP-, CRM- oder anderen Systemen wie beispielsweise dem zentralen Data Warehouse weitere Informationsquellen, die in die Analytics mit eingebunden werden. Dies können nicht selten Datenbestände sein, die man im Allgemeinen dem Begriff Big Data zuordnet.
Konkret bezeichnet Big Data eine bestimmte Art und Beschaffenheit von Daten plus dazu passende Methoden und Technologien für die hochskalierbare Erfassung, Speicherung und Analyse. Gerne wird in dem Zusammenhang auch von den drei Vs gesprochen:
- Variety oder die Datenvielfalt: Immer mehr Daten liegen in unstrukturierter und semistrukturierter Form vor, beispielsweise aus den sozialen Netzwerken oder auch Geräten und Sensoren.
- Volume oder die Datenmenge: Immer größere Datenvolumina werden angesammelt – Größenordnungen von mehreren Petabytes sind keine Seltenheit mehr.
- Velocity oder die Geschwindigkeit: Riesige Datenmengen müssen immer schneller ausgewertet werden, bis hin zur Echtzeit. Die Verarbeitungsgeschwindigkeit muss mit dem wachsenden Datenvolumen Schritt halten.
Bezieht man also neben strukturierten Daten auch unstrukturierte, polystrukturierte und Massendaten, idealerweise realtime in die Analyse mit ein und bedient sich dafür unter anderem der Methoden des Machine Learnings, erweitert man die BI durch Big Data und den Einsatz von AI hin zur Advanced Analytics.
Viele spannende Informationen warten darauf, auf diese Art von Ihnen entdeckt zu werden!
Mein Tipp: Sie wollen den Machine Learning Algorithmen auf den Grund gehen? Holen Sie sich das kostenfreie QUNIS Machine Learning Cheat Sheet als PDF, im Pocket-Format oder als Poster für die Wand. Hier direkt QUNIS MACHINE LEARNING CHEAT SHEET holen.